
ORKG Ask – KI auf der Suche nach Antworten in Open Access Artikeln
Die Suche nach Antworten auf wissenschaftliche Fragestellungen gleicht oft der Suche nach der Nadel im Heuhaufen. KI-basierte Systeme können hier Abhilfe schaffen. Das Wissen, auf das sie dabei zurückgreifen, sollte frei verfügbar sein.
Jedes Jahr erscheinen mehrere Millionen neue Forschungsbeiträge. In dieser Flut an Publikationen fällt es Forschenden zunehmend schwer, den Überblick zu behalten. Gesucht werden Antworten auf Forschungsfragen, doch traditionelle Suchsysteme liefern nur eine Auflistung möglicherweise relevanter Dokumente. Immer mehr Forschende und Studierende setzten daher bei der Beantwortung von Forschungsfragen auf KI-Systeme, spezifisch solche, die auf großen Sprachmodellen basieren.
Doch eine naive Anwendung von beispielsweise ChatGPT führt oft nicht zum gewünschten Ergebnis. Quellen fehlen häufig, werden falsch verwendet oder sind sogar vollständig erfunden. Auch das von Meta spezifisch für die Wissenschaft entwickelte Modell „Galactica“ überstand gerade mal drei Tage, ehe es aufgrund von Falschaussagen deaktiviert wurde.1 Das liegt daran, dass Sprachmodelle kein echtes Verständnis für das Wissen, das zur Beantwortung einer Forschungsfrage benötigt wird, entwickeln, sondern lediglich auf Basis von wahrscheinlichen Wortabfolgen antworten. Dieser Ansatz funktioniert gut für Fragen des Allgemeinwissens, da diese inklusive der zugehörigen Antworten vielfach in den Trainingsdaten dieser Sprachmodelle vorkommen. Wissenschaftliche Themen, die hingegen deutlich seltener diskutiert werden und zudem höheren Anforderungen an Präzision und Detailgrad gerecht werden müssen, können jedoch nicht vollumfassend abgedeckt werden, wenn man sich lediglich auf die Antwort eines Modells ohne weitere Informationsquellen verlässt.
Der nächste Schritt ist also, zur Generierung der Antworten zusätzliche Informationsquellen anzuzapfen. Für die Wissenschaft sind dies Publikationen. Dieses Verfahren heißt Retrieval-Augmented-Generation. Dabei wird zunächst gezielt Wissen aus konkreten Quellen abgerufen (retrieval), bevor ein Sprachmodell aus diesen Informationen eine Antwort formuliert (generation). Das unterscheidet sich fundamental von der reinen Textgenerierung großer Sprachmodelle, bei denen nicht klar ist, woher die Informationen stammen.
Der von der TIB entwickelte KI-Assistent ORKG Ask ermittelt seine Antwort auf Basis veröffentlichter Artikel. Nachdem Forschende ihre Frage eingegeben haben, werden zunächst über eine semantische Suche die relevantesten fünf der knapp 80 Millionen enthaltenen Publikationen bestimmt. So ist sichergestellt, dass nur tatsächlich existierende Quellen herangezogen werden. Erst dann wird ein Sprachmodell herangezogen, um Antworten aus diesen fünf Artikeln dieser Auswahl zu extrahieren. Daraus werden eine Kurzantwort in etwa 3-5 Sätzen sowie eine detaillierte tabellarische Übersicht über die Inhalte und Antworten der einzelnen Veröffentlichungen erstellt. Bei Bedarf können mehr Publikationen geladen sowie weitere Details zur Tabelle hinzugefügt werden.
Während die Bewertung der Relevanz zunächst nur nach inhaltlicher Übereinstimmung erfolgt, können Nutzende anschließend nach weiteren Eigenschaften wie beispielsweise der Anzahl der Zitierungen, bestimmten Autor*innen oder dem Erscheinungsjahr filtern.
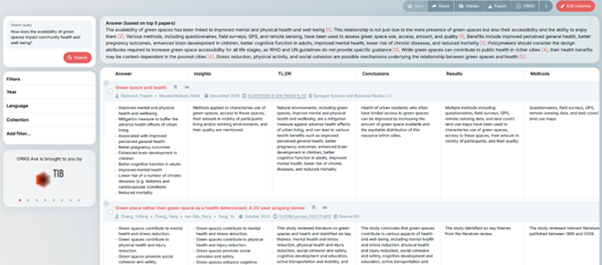
Als Datengrundlage für ORKG Ask dient das CORE-Dataset, die weltweit größte Sammlung an Open-Access-Artikeln. Der Datensatz enthält die Abstracts von knapp 80 Millionen Artikeln, bei knapp 20 Millionen davon liegen ebenfalls Volltexte vor. Durch die Verwendung von Open Access entstehen keine rechtlichen Probleme. Hingegen ist die Rechtslage bei Closed-Access-Artikeln nicht abschließend geklärt. Zwar werden die Artikel in ORKG Ask nicht dazu genutzt, das Modell weiter zu trainieren, doch befindet sich auch das Extrahieren von Informationen in einer Grauzone. Lizenzen und Vorgaben der Verlage müssten im Einzelnen geprüft werden. Durch die Beschränkung auf Open Access fallen diese Hindernisse weg.
Im Zuge der rasanten Entwicklungen im Bereich generativer KI werden in sämtlichen Bereichen Fragen des Copyrights, des Datenschutzes und der Datenethik neu diskutiert. Besonders in der Wissenschaft spielen auch Transparenz und Reproduzierbarkeit von KI-generierten Ergebnissen eine große Rolle. Ein Frage-Antwort-System sollte kein verstärkender Faktor der Reproduzierbarkeitskrise2 werden. Deswegen setzt die TIB bei der Entwicklung des ORKG Ask auf Openness. Nicht nur Ask‘s Quellcode ist Open Source, sondern auch sämtliche verwendeten Dritttechnologien. Als Sprachmodell kommt das in der EU entwickelte offene Modell Mistral zum Einsatz. Sämtliche Prompts, die das System zur Abfrage von Informationen durch das Sprachmodell nutzt, können von Nutzenden eingesehen werden. Auch ist deutlich gekennzeichnet, welcher Kontext (Abstract oder Volltext) herangezogen wird, um die präsentierte Information zu gewinnen. Ebenso können sämtliche verwendete technische Parameter, die dem Modell übergeben werden, wie beispielsweise der Seed, der den Zufallsprozess reproduzierbar macht, ausgelesen werden.
Wie bei jedem Einsatz von großen Sprachmodellen besteht zwar die Gefahr von Halluzinationen in den einzelnen Spalten der Antworttabelle oder in der Kurzzusammenfassung, jedoch existieren alle angezeigten Artikel wirklich. Nutzende werden dazu aufgefordert, gegebene Antworten zu verifizieren, indem sie den Originalartikel lesen. Auch hier ist von Vorteil, dass es sich im Datensatz um Open-Access-Veröffentlichungen handelt.
Als Service der TIB ist ORKG Ask nicht-kommerziell und steht kostenfrei und ohne Anmeldung zur Verfügung. Derzeit wird an einer mehrsprachigen Ausgabe und an einer Anpassung an das individuelle Vorwissen der Nutzenden gearbeitet. So kann Ask in Zukunft nicht nur Fragen von Forschenden, sondern auch der interessierten Öffentlichkeit beantworten.
Zusammenfassend lässt sich festhalten, dass KI-Systeme für die Wissenschaft nicht nur maßgeblich von der Open-Access-Bewegung profitieren, sondern auch selbst so offen wie möglich sein sollten, um durch Transparenz und Reproduzierbarkeit das Vertrauen in die KI-generierten Antworten zu stärken. Open Access schafft dabei nicht nur rechtliche Gewissheit, sondern erleichtert auch die kollaborative Bewertung und Einordnung der generierten Antworten durch Forschende. Nur wenn die verwendeten Daten offen einsehbar sind, können Aussagen von KI-Systemen geprüft, Fehler gefunden und Antworten verbessert werden. So tragen Open-Access-Artikel wesentlich dazu bei, KI-Systeme vertrauenswürdiger zu gestalten und Falschinformationen zu beheben.
1 https://www.technologyreview.com/2022/11/18/1063487/meta-large-language-model-ai-only-survived-three-days-gpt-3-science/
2 Die Reproduzierbarkeitskrise bezeichnet das Problem, dass viele wissenschaftliche Studien nicht zuverlässig durch andere Forschende wiederholt bzw. Ergebnisse nicht bestätigt werden können. Gründe hierfür sind unter Anderem methodische Schwächen, eine unzureichende Dokumentation der Arbeit und fehlende Transparenz.
Zitiervorschlag
Lorenz, A. (2025). ORKG Ask – KI auf der Suche nach Antworten in Open Access Artikeln. open-access.network. doi.org/10.64395/d3ar7-pd371.
Dieser Beitrag ist lizenziert unter der Creative Commons Namensnennung 4.0 International Lizenz (CC BY 4.0).

Schreibe einen Kommentar
Kommentare
Keine Kommentare
